-
[Kafka 101] 카프카 커넥트 (Kafka Connect)개발자 라이프/카프카 2020. 5. 10. 12:57반응형

들어가며
카프카는 프로듀서와 컨슈머 클라이언트를 통해 메시지 파이프라인을 구성할 수 있습니다. 하지만 파이프라인 구성을 위해 매번 프로듀서와 컨슈머를 개발하는 것은 쉽지 않습니다. 이번 글은 카프카와 외부 시스템 간의 파이프라인 구성을 더욱 쉽고 간편하게 해주는 카프카 커넥트(Kafka Connect)에 대해서 살펴봅니다.
Kafka Connect
카프카는 아키텍처 중심에서 다양한 외부 시스템과 메시지 파이프라인을 구성합니다. 그리고 일반적으로 메시지를 송수신하기 위해 외부 시스템에는 프로듀서, 컨슈머가 구현됩니다. 이때, 외부 시스템의 수가 많아지면 어떻게 될까요? 클라이언트는 그 외부 시스템에 맞춰 구현되고 관리되어야 합니다. 즉, 개발 비용이 필요합니다. 카프카 커넥트는 이러한 개발 비용을 없애고, 쉽고 간단하게 메시지 파이프라인을 구성할 수 있도록 도와주는 아파치 카프카 프로젝트 중 하나입니다.
Connect 구성하기

커넥트를 통한 메시지 파이프라인 구성. 카프카 커넥트는 카프카 브로커 클러스터와 별도로 구성됩니다. 커넥트는 단일 모드(Standalone)와 분산 모드(Distributed)로 구성할 수 있으며, 일반적으로 단일 모드는 개발 테스트 환경에서 사용하고, 분산 모드는 운영 환경에서 사용합니다. 분산 모드를 사용하게 되면 커넥트 클러스터 내부에서 작업이 자동으로 분산 동작하게 되고, 장애가 발생했을 경우 자동으로 노드 간 작업이 이관합니다. 분산 모드를 구성하는 방법은 쉽습니다. 같은 카프카 클러스터를 바라보고(`bootstrap.servers`), 같은 그룹 아이디로 지정하면(`group.id`) 같은 작업 내역을 공유하는 카프카 커넥트 클러스터를 구성할 수 있습니다.
Connect를 이용한 메시지 파이프라인 구성
커넥트는 2가지 형태로 메시지 파이프라인을 구성합니다.
- Source Connector : 외부 시스템 -> 커넥트 -> 카프카
- Sink Connector : 카프카 -> 커넥트 -> 외부 시스템
커넥터(Connector)는 커넥트 내부의 실제 메시지 파이프라인입니다. 커넥터에 대한 정의는 혼용되기 때문에 자세한 내용은 내부 구조 단락에서 다룹니다. 아무튼 커넥'트'에 커넥'터'를 구성하기 위해선 커넥'트'에 커넥'터' 관련 설정(property) 명세를 전달하면 됩니다. 단일 모드의 경우 파일 형태로, 분산 모드의 경우 REST API를 통해 전달할 수 있습니다. 아래는 분산 모드에서 JDBC Sink Connector를 구성하기 위한 REST API 호출 예시입니다. (JDBC Sink Connector는 특정 토픽의 메시지를 대응되는 DB 테이블에 Sink 하기 위한 커넥터입니다.)

JDBC Sink Connector 생성 예시. 관련 설정 값을 명시하여 전달한다. 위 요청을 받은 커넥트는 설정 값에 맞게 커넥터를 구성합니다. 설정 값은 모든 커넥터에 필수인 설정과 커넥터 별 설정이 있습니다. 예를 들어, 위 요청은 JDBC 관련된 커넥터를 생성하는 요청이기 때문에 connection에 관련된 설정이 필요합니다. 만약 File sink connector를 구성했다면, 파일 경로 설정이 들어갑니다.
구성된 커넥터는 주기적으로 메시지를 확인하고, 새로운 메시지가 있으면 파이프라인을 통해 흘려보냅니다. 위 예시의 경우 `target.*` 정규식에 해당하는 모든 토픽에 메시지가 들어오면, 각 토픽 별 테이블에 주기적으로 Sink 합니다. 참 쉽죠?
내부 구조

커넥트 내부의 커넥터를 통해 메시지 파이프라인이 구성됩니다. 눈치가 빠르신 분은 아셨겠지만 커넥트는 일종의 템플릿이 구현되어 있고, 그 템플릿과 설정 값을 기준으로 인스턴스를 생성하는 방식입니다. 커넥트에서는 그 템플릿을 플러그인(plugin)이라고 정의합니다. 즉, 커넥트는 코드로 구현된 플러그인에 환경에 맞는 설정을 하여 인스턴스를 생성합니다. 이와 관련된 다양한 내부 구성요소들이 있는데, 다음과 같습니다.
- 커넥터 (Connector) : 파이프라인에 대한 추상 객체. task들을 관리
- 테스크 (Task) : 카프카와의 메시지 복제에 대한 구현체. 실제 파이프라인 동작 요소
- 워커 (Worker) : 커넥터와 테스크를 실행하는 프로세스
- 컨버터 (Converter) : 커넥트와 외부 시스템 간 메시지를 변환하는 객체.
- 트랜스폼 (Transform) : 커넥터를 통해 흘러가는 각 메시지에 대해 간단한 처리
- 데드 레터 큐 (Dead Letter Queue) : 커넥트가 커넥터의 에러를 처리하는 방식
앞서 설명한 플러그인은 커넥터에 해당합니다(정의를 혼용합니다). 즉, 구현된 커넥터를 이용하여 인스턴스를 생성하면, 커넥트 워커 프로세스 내부에 테스크들이 생성되고 파이프라인이 구동됩니다. 테스크 내부에는 외부 시스템 간 메시지를 변환하는 컨버터가 구성되고, 필요하다면 트랜스폼을 통해 간단한 처리를 실시합니다.

Source 파이프라인의 추상화된 흐름. (출처 : https://docs.confluent.io/current/connect/concepts.html) 주의점
커넥'터'를 고려하거나 구성할 때는 몇가지 주의해야 할 점이 있습니다.
- 외부 시스템을 지원하는 플러그인이 있는지?
- 플러그인의 라이센스는 어떻게 되는지?
커넥트는 구현된 플러그인을 이용하여 파이프라인 인스턴스를 구성하기 때문에, 해당 플러그인이 제공되고 있어야 합니다. 그리고 플러그인은 Source/Sink 따로 제공되는 경우가 많으므로, 파이프라인 구조와 함께 고려되어야 합니다. 제공되는 플러그인은 confluent.io/hub에서 쉽게 확인할 수 있습니다. 필요하다면 직접 구현할 수 있는데, Confluent Docs를 참고하시기 바랍니다.
그리고 플러그인은 제공하는 업체 혹은 커뮤니티가 각각 다르기 때문에 라이센스 또한 각각 다릅니다. 그렇기 때문에 커넥터를 고려할 때 꼭 라이센스 부분도 같이 확인하시길 바랍니다.
JDBC Connector는 Source와 Sink 모두 지원하고, 무료로 사용할 수 있습니다. 마무리
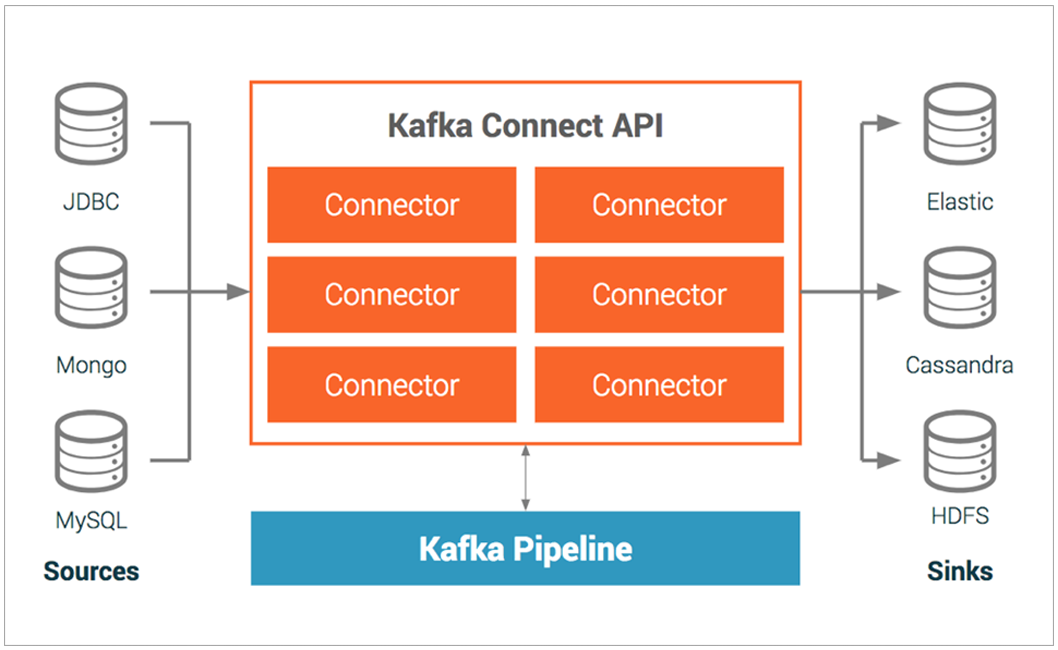
Connect를 이용하여 외부 시스템 간 파이프라인 구성 (출처 : leadsoft.co.kr) 커넥트는 이미 구현된 플러그인에 환경에 맞는 설정 값만 넣어줌으로써 쉽고 간편하게 파이프라인을 구성할 수 있습니다. 이는 복잡한 로직이 없는 파이프라인 구성에 큰 강점을 가지는데, 특히 ETL과 CDC 파이프라인 구성에 매우 적합합니다. 다만, 주의점 단락에서 언급했듯이 플러그인 별로 라이센스가 다르니 도입 전에 꼭 살펴보시길 바랍니다.
ps 1. 혹시 잘못되거나 부족한 부분은 댓글로 남겨주시길 바랍니다.
ps 2. 내용이 마음에 드셨다면 공감 버튼❤️을 눌러주세요!반응형