-
[Kafka 101] 카프카 스트림즈 (Kafka Streams)개발자 라이프/카프카 2020. 5. 24. 14:44반응형

들어가며
카프카는 브로커를 중심으로 다양한 형태의 메시지 파이프라인을 구성할 수 있습니다. 그리고 메시지 파이프라인은 보편적으로 메시지를 생성하고 브로커로 전송하는 프로듀서에서 시작하여, 브로커에 저장된 메시지를 읽고 처리하는 컨슈머에서 끝이 납니다. 즉, 브로커 외부에서 메시지가 생성되고, 다시 브로커 외부로 읽어집니다. 이러한 메시지 파이프라인 구성은 프로듀서와 컨슈머를 직접 개발하거나, 혹은 카프카 커넥트(Kafka Connect)를 이용하여 Source -> Sink 형태로 구성할 수 있습니다.
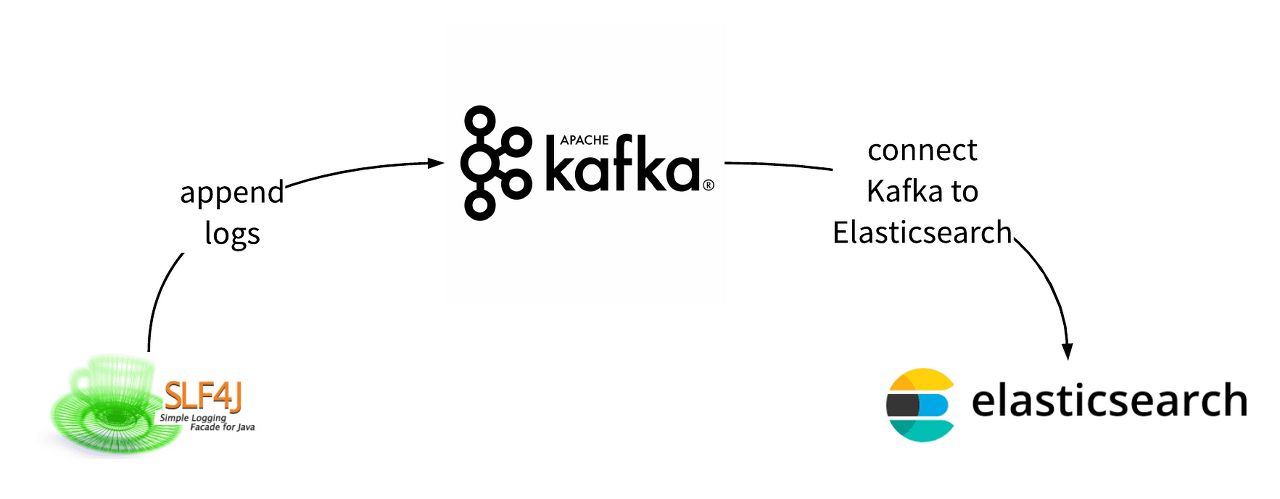
가장 일반적인 카프카 사용 사례(로그 수집). 외부에서 생성된 로그 데이터가 브로커를 통해 Elasticsearch로 적재된다. (출처 : https://www.splunk.com/en_us/blog/it/how-to-migrate-apache-kafka-applications-to-apache-pulsar.html) 그렇다면 카프카 내부에서 메시지 파이프라인을 구성하려면 즉, 내부 토픽을 이용하여 파이프라인을 구성하려면 어떻게 해야 할까요? 이번 글은 카프카 내부에서 메시지 파이프라인을 쉽게 구성할 수 있도록 하는 카프카 스트림즈(Kafka Streams)에 대해 살펴봅니다.
카프카 스트림즈 (Kafka Streams)
카프카 스트림즈는 Streams API 라이브러리입니다. 그렇기 때문에 프레임워크에 종속되지 않고, 라이브러리 의존성을 추가하여 몇 가지 설정만 해주면 알아서 파이프라인이 구성됩니다. 그렇다면 카프카 스트림즈는 주로 어떤 형태의 메시지 파이프라인을 위해 고려할 수 있을까요? 아래 Spring Kafka 프레임워크를 기반으로 Streams API로 구성한 애플리케이션의 코드 블럭을 예로 들어 설명하겠습니다. 참고로 제가 Spring Kafka 문서에 기여한 내용입니다 ㅎㅎ ;)
- line 9 : kStreams 메소드는 StreamBuilder 객체를 이용하여 메시지 파이프라인(스트림)을 구성하여 반환합니다.
- line 10 : streamingTopic1 토픽에 저장된 데이터들을 기점으로 스트림을 구성합니다.
- line 12 ~ 19 : 스트림(stream)의 로직(=토폴로지, Topology)을 메소드 체이닝을 통해 구성합니다.
- line 20 : 스트림의 결과를 StreaminigTopic2 토픽으로 흘려보냅니다.
위와 같이 스트림은 브로커의 특정 토픽을 Sub 하여 일련의 로직을 처리한 뒤, 다시 다른 토픽으로 Pub 합니다. 즉, 카프카 내부 토픽을 기준으로 메시지 파이프라인을 구성합니다. 이는 일반적으로 Pub/Sub하는 모습과 다른 모습입니다. 이처럼 카프카 스트림즈는 카프카 내부 파이프라인을 더욱 쉽게 구성할 수 있도록 하는 API 라이브러리입니다.

카프카 내부 파이프라인을 위해 사용되는 카프카 스트림즈 (출처 : confluent.io) 카프카 스트림즈의 기능
스트림즈는 다음과 같은 파이프라인 구성에 고려될 수 있습니다.
- 토픽 내부의 민감 데이터 마스킹
- 다양한 Source로부터 수집된 메시지 규격화
- 5분 간격으로 토픽 내부의 특정 이벤트 감지
- 특정 필드를 이용한 파이프라인 조인
위와 같은 기능을 구현할 수 있도록 Streams API는 filter(), map(), groupBy() 등 다양한 처리, 집계 함수를 제공하고 있습니다. 특히 집계 함수의 경우 메시지 키 별, 시간 간격 별 등으로 집계할 수 있으며, 집계 상태 정보를 저장하는 상태 저장소(State Store)가 사용됩니다. 스트림즈의 상태 저장소에 대한 설명은 별도의 글로 정리하도록 하겠습니다.
카프카 스트림즈의 구성
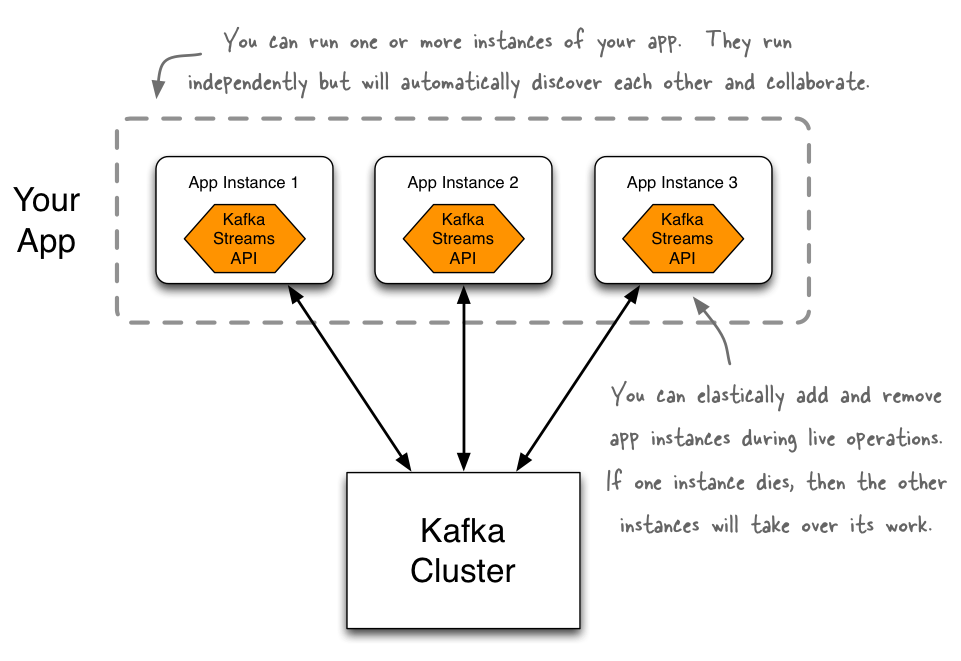
브로커 클러스터 외부에 구성되는 카프카 스트림즈 애플리케이션 (출처 : https://docs.confluent.io/current/streams/introduction.html) 카프카 스트림즈는 Streams API로 구축된 애플리케이션으로, 브로커와 별도로 구성됩니다. 그리고 라이브러리로 제공되므로 단순히 main 함수 내에서도 구현 가능하며, 특정 프레임워크에 종속되지 않습니다.
카프카 스트림즈 애플리케이션은 확장에 유연하고, 장애 수용성(fault-tolerant)을 가지며, 분산 형태로 구성할 수 있습니다. 스트림 애플리케이션이 이렇게 안정적이고 확장적인 구성을 할 수 있는 이유는 내부적으로 Consumer API를 사용하기 때문입니다. Consumer는 consumer group 기능을 통해 자동적으로 토픽 파티션 소유권을 관리합니다. 스트림즈 애플리케이션 또한 인스턴스의 증감에 따라 토픽 파티션에 대한 소유권을 자동적으로 관리합니다. 그렇기 때문에 효과적이고 안정적인 파이프라인을 구성할 수 있습니다.
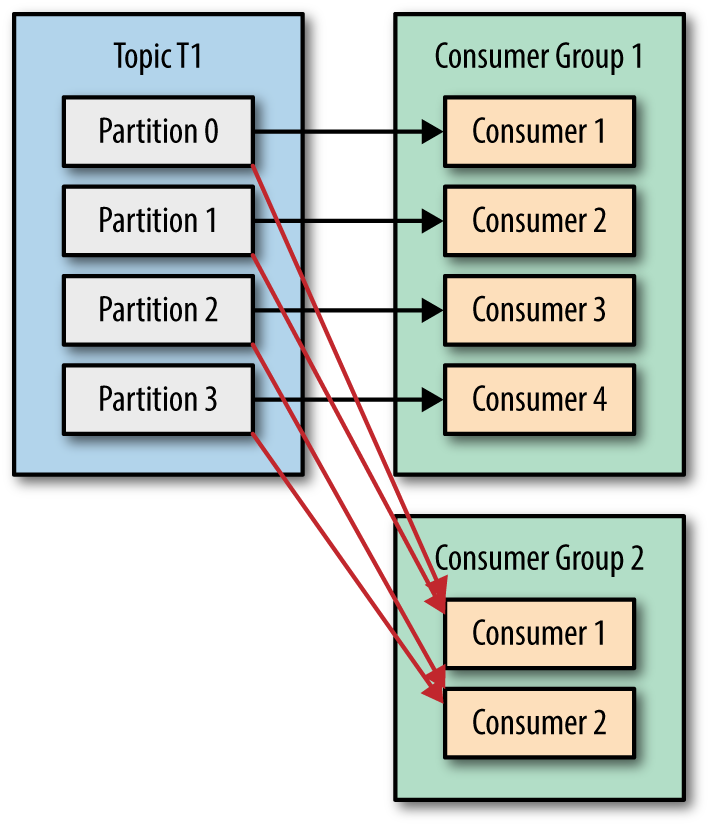
컨슈머 그룹 기능을 이용한 토픽 파티션 소유권 자동 분배 (출처 : https://www.oreilly.com/library/view/kafka-the-definitive/9781491936153/ch04.html) 카프카 스트림즈의 구현
카프카 스트림즈는 Streams API를 이용해서 메시지 파이프라인 로직(토폴로지)을 구현합니다. 다만, 추상화 정도에 따라 2가지 방식으로 구현할 수 있습니다.
- Stream DSL
- Processor API
Stream DSL은 미리 제공되는 함수들을 이용하여 토폴로지를 정의하는 방식으로, 앞서 살펴본 예제 코드도 Stream DSL 방식을 이용한 코드입니다. Stream DSL은 Processor API 보다 비교적 추상적이며 사용하기 쉽습니다. 이와 반대로 Processor API는 정의된 함수를 사용하지 않고 직접 구현해야 하기 때문에 사용하기 어렵습니다. 하지만 Stream DSL 보다 정교한 로직을 녹여낼 수 있는 장점이 있습니다. 아래는 Processor API를 이용한 단어 집계 프로세서 구현 예제입니다. 얼핏 봐도 위 예제보다 복잡한 느낌입니다.
마무리
카프카는 브로커를 중심으로 다양한 형태의 파이프라인이 구성될 수 있습니다. 이번 글을 통해 카프카 내부 파이프라인을 구성할 때, 더욱 쉽게 구성할 수 있도록 도와주는 카프카 스트림즈의 배경, 기능, 구성, 구현에 대해 (정말) 간단히 살펴봤습니다. 보다 자세한 내용은 각각 별도의 글로 만나 뵙도록 하겠습니다. :)
ps 1. 혹시 잘못되거나 부족한 부분은 댓글로 남겨주시길 바랍니다.
ps 2. 내용이 마음에 드셨다면 공감 버튼❤️을 눌러주세요!반응형